NDS汉化小白教程 —— fengarea(A9VG汉化组)
https://bbs.a9vg.com/thread-501522-1-1.html
写这个教程的主要目的是让更多的人了解汉化工作和加入到汉化工作中。
这个叫汉化小白教程,不是说这个教程是给小白看的,也不是说看这个教程的就是小白。只是说写这个教程的人很小白,这个教程能教大家的东西并不多,都是比较小白的东西。当然每个人的水平和专长都不一样,所以说不定里面的一些东西还是有点参考价值的。总之,有不妥或不足是一定的,还望大家多指教。
考虑到教程已经出来几话,为了检索方便做一个索引:
索引
第一话:基础理论和知识
——本话主要介绍一些关于汉化NDS游戏的基础理论和知识。
第二话:CT教程+ROM解读
——本话介绍的是汉化工具CT的基本操作和ROM解读的基础。
第三话:字库码表篇•初步
——本话主要是关于汉化中对游戏字库的解读和修改,以及文本码表的基本知识。
其他教程将陆续添加……
第一话:基础理论和知识
https://bbs.a9vg.com/thread-494124-1-1.html
超执刀的工作已经进入静待翻译进度,JSS也是一个候稿的时候,所以一时闲了一点。
记得很早就说过当超执刀汉化到一定阶段就要写个教程什么的。所以就到这里喷喷毒了。
这个叫汉化小白教程,不是说这个教程是给小白看的,也不是说看这个教程的就是小白。只是说写这个教程的人很小白,这个教程能教大家的东西并不多,都是比较小白的东西。当然每个人的水平和专长都不一样,所以说不定里面的一些东西还是有点参考价值的。总之,有不妥或不足是一定的,还望大家多指教。
第一话主要是一些很基础的知识,后面会陆续写关于图片HACK,ROM HACK,文本导出导入等部分。当然写教程截图比较麻烦……所以不知道什么时候才能完成,希望各位慢慢等待了。
废话少说,那么开始吧。
一、干嘛要汉化
每个人做汉化的理由的不一样,挑战自我,服务群众,纯粹为好玩……当然结果是一定的,不少玩家能在汉化中受益,能以自己引以为豪的母语来更好地体会游戏的乐趣。我要说的是,一个汉化工程,即使是半途而废,但也是非常有意义的,就是在其中可以学到不少游戏知识,里面的汉化经验都能未未来的汉化开创更好的道路。所以有能力的朋友,请多多加入汉化的行列,无需顾虑太多,每一分参与都将为汉化界带来动力。我这个水平也要写这篇教程献丑,也是因为想鼓励更多朋友加入到汉化工作中。
二、汉化需要什么人才?
答案是:任何人都需要!
汉化是一个复杂的综合工程。每一个环节都需要不同的人帮忙,相对的,不同特长的人都能加入进来。
如果对编程,或者修改游戏比较有心得的,可以加入到ROM HACK的部分。
如果对翻译比较有能力的可以加入到翻译的部分。
如果对改图比较有心得的,可以加入到美工的部分。
如果对语言能力比较有自信的,可以加入到润色的部分。
如果对统筹能力比较有自信的,可以加入到项目运作统筹的部分。
如果对耐心比较有自信,可以加入到文本整理的部分。
如果对自己游戏能力比较有自信,可以加入到游戏测试的部分。
总之任何人都可以加入到汉化工作中,汉化工作也需要任何人。
当然,汉化项目最重要的是耐心与责任心。有机会加入到汉化项目里面相信就会明白这话的含义了。
以致于我经常有这个感觉:一个汉化游戏能否成功,关键并不在于技术力,而在于怨念的强度……
我们汉化组的群我改名为手术室,一方面是因为汉化是关于《超执刀》这个手术游戏,另一个方面也在于提醒自己汉化是一个团队的合作,自己对一起战斗的小组成员有责任,对手术台上面的游戏也有着责任,绝不能轻易放弃!
那么废话少说,正式开始教程部分,下面我会针对不同的部分分别写些教程(或流程),首先的是ROM HACK的部分。
三、ROM HACK是什么?
ROM HACK就是对游戏ROM进行破解,我喜欢简称为ROM H,一方面HACK这个词太崇高了,其实ROM HACK根据程度不同,可以是很简单的解读或者很深奥的深度破解ASM HACK(这才是真正意义上的HACK),一般情况下,汉化并不一定需要这么深入,所以无需说得太玄。令一方面H的含义有更多,我比较喜欢的说法就是“H=干”。H一个ROM就是干与这个ROM有关的工作。
希望各位能从上面这段不着边际的话里面看到一些ROM HACK的概念。也就是其实ROM HACK并不一定要求很高,最基础的是进行ROM的解读就行。
四、ROM HACK基础
ROM HACK需要什么基础呢?其实一个修改过游戏,对16进制有点认识的人基本就已经具备了ROM HACKER的基础了。如果你能懂一些编程的基础,那么你就更有可能成为强大的ROM HACKER。
当然要正式做ROM H,还需要一些基本功。
下面我推荐一些教程,基本我也是从这些教程里面学习ROM H的基础的。
分别是:狼组的教程,天使组的教程,PGCG的教程,真空实验室-yeyezai(实验小白鼠)的教程。
当然这些教程不少并不是针对NDS的,但无论是FC,SFC,GBA还是其他,汉化的不少原理是共通的,尤其是GBA的,对NDS实在太有参考价值了。
另外多泡一些汉化论坛,多跟汉化达人们交流也是迅速提高自己H能力的方法。
汉化工作对自学能力要求也是相当高的,从不同的教程中学习需要的能力,充实自己吧。
当然这些教程也不是要一下子看明白,与其纯粹纸上谈兵,还不如拿一个ROM研究一下实际。
我推荐的是《超执刀》的ROM,这个ROM实在太厚道了,厚道得完全是为汉化初手而存在的一般。
略略充实一下自己之后,就可以到下一部分了。
五、NDS汉化的特殊性
相信很多人有疑问,为什么GBA这么多汉化作品,NDS的这么少呢?
这是因为NDS有着它的特殊性。首先是ROM的变大,让汉化研究的平台要求有所提高。
然后是模拟器的不成熟,DEBUG是非常困难的,涉及ASM HACK的完美破解因为常常需要DEBUG数据,所以不少游戏无法做到完美破解(对于完美主义者是相当大的挫折啊)。
也是上述原因,涉及图片的色版提取,文件提取等都相对比较多困难。
另外,最大的困难莫过于无法很好地进行字库移动和扩容。
当然,由于系统的变化,原来的一些汉化数据(即使是非常近似的GBA)也变得不再适用,一些研究又回到原点。这相信也是一个原因。
对付这些问题,自然就需要破解者有更灵活的头脑,巧妙地化解一些难题,攻克一些新难题。总之学习能力,恒心,耐心在这时候就意义重大了。
另外,也因为现在NDS汉化资源相对贫乏,如我之前所说的,任何人的一些汉化研究意义也是非常重大的。
六、ROM H的主要任务
ROM H需要承担的主要是汉化工作的以下任务:有针对性的查找资料做好准备吧。
1、解读判明ROM的基本结构
例如哪里是字库,哪里是图片(分别对应那些图片),哪里是文本区,哪里是声效区……如果文件系统比较复杂的ROM,不同文件分别是什么内容也要进行判明。
另外有的游戏不同文本对应不同字库,这些都是需要认真确认的内容。
有的ROM可能有压缩过的内容,如果这些内容涉及汉化的需要,这时还需要进行解压和压缩的测试。
一般这个阶段我是会准备几张大纸进行详细记录的,这样为以后的工作将带来很大方便。
2、字库HACK
这个是关系到汉化可能性的最关键部分。一般游戏的字库有分完整字库和精简字库。完整字库里面包含了7000多个字符(其中6000多个汉字),而精简字库一般只有1000-2000个游戏里面实际运用到的字符。无论那个字库,由于日语汉字缺乏不少中文常用字,都必须修改,而精简字库更需要大改造,甚至扩容。后面的教程会专门针对字库HACK进行讲解,此处暂时打住。
3、文本试验
汉化,就是用中文替换原来的日本语内容,所以需要对这个替换的可能性进行试验。当然,初步破解不一定要很正经的进行文本导出导入,或翻译修改,只需看看有没有修改的可能性就行。前面提到的不少教程都有涉及这方面的操作,可以仔细研究。
4、图片HACK
这个视乎小组分工不同,如果美工本身有破解能力的话,可以由美工负责(据我所知,不少破解都兼任美工,可能ROM H本身就需要一定对图形的敏感吧),作为负责这部分内容,需要注意的主要就是图片拼组,色版处理等。另外一些需要汉化的关键图片(图片里面有需要汉化内容的)必须找出来。另外还可能需要为美工做好色版导出,图片导出等准备工作。也可以进行一些图片修改的试验。
如果上面的部分准备完成,并测试成功,那么恭喜,这个汉化项目已经成为可能。可以正式招募人才和推进下一步工作了。
基础的东西就先说这么多,下一话就是NDS ROM H的利器,CT(CrystalTile)的教程。敬请期待。
第二话:CT教程+ROM解读
https://bbs.a9vg.com/thread-495606-1-1.html
本话主要是针对ROM H里面涉及解读ROM,先让各位简单了解一下CT这个工具。
一、CT的强大功能
CT全称CrystalTile,是由天使组的Crystal在过去的tile工具的基础上不断改进的成果。可以说是汉化GBA/NDS游戏非常好用的工具。
另外它还综合了差值搜索,LZ77解压,等不少有用的功能,而且还特意为汉化NDS游戏进行了优化。
另外这个工具的版本还不断修正更新,我用的是5月中的版本,写本文的时候又更新了几个版本了。
其实以前的TILE工具的一些操作在CT上面是通用的,那些工具都有一些网上的教程,但对于没有接触过的朋友,也作为CT这个新工具的介绍,所以我这里就专门简单介绍一下。
下面就是CT的界面:
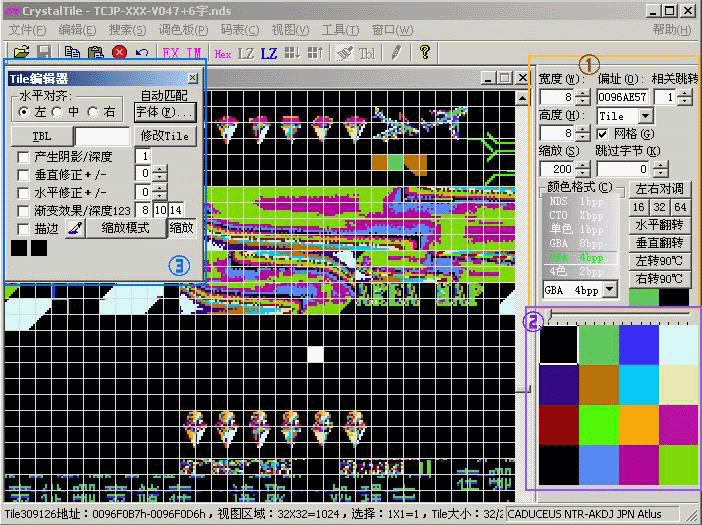
①的区域是导航栏的主部分,最主要的是偏址,即偏移地址,另外还有颜色格式,颜色格式关系到能否正确查看ROM的图形部分的内容,汉化NDS游戏常用的是1bpp单色,GBA 4bpp,GBA 8bpp这几种
(1bpp单色主要针对的是字库的内容)
②的区域就是显示色版,关系到能否正确显示图形里面所对应颜色。可以在调色版菜单里面进行调整或回复默认。直接点击里面的颜色,可以进行直接修改。如果是非256色的色板,上部的横拉杆还可以读取总色版(256色)的不同部分来进行匹配。
③的区域是TILE工具,可以进行简单的TILE修改,同时CT在这里还集成了通过码表生成字库的强大功能。(如果平时用不上TILE功能,可以隐去这个窗口腾出工作空间)
中部的就是打开的ROM的内容了。
现在ROM是以TILE模式打开的,也就是可以直接观察里面的TILE内容(字模,图形……)
菜单栏下面是快捷工具栏

分别是
①导出按钮,这个按钮可以让CT导出选定的内容到一定格式的文件,常用的是将选定的图形区域内容导出为BMP文件,但CT的导出功能可不仅限于导出图片哦。具体的内容在图片H教程会进一步讲解。本篇只需有个大体概念就行了。
②导入按钮,对修改好的图片,例如BMP图片,导入回ROM里面的指定区域。
③16进制编辑器快速切换按钮,可以快速切换到16进制模式
④LZ77解压按钮,对选定的LZ77内容解压
⑤LZ77压缩按钮,将选定的内容进行LZ77压缩
⑥将色版转换为16/32数据导入
⑦将16进制方式存放的色版导出为PAL色版文件
⑧对编码染色
⑨应用码表开关
其中④⑥⑦⑧⑨只能在16进制视图模式才可以使用。
打开视图菜单,可以把工作ROM的视图转换到其他模式。
下面我们切换到16进制模式,看看CT的16进制编辑功能。
CT跟一般的16进制编辑器很像(虽然不及UE强大),但却结合汉化进行了优化。
例如进行了编码染色。非常方便查看,有经验的美工,甚至可以直接通过被染色的编码马上就能找到色版数据的开头,进行色版导出(后面的美工教程会有进一步介绍)。另外在文本区域中间,也能很容易找到特殊控制符的内容(例如下面的例子中的F1FF等控制符就被染色为浅蓝色,与一般文字区别开来了)。
另外一个很有用的功能就是直接套入码表来显示文本区的大体内容:
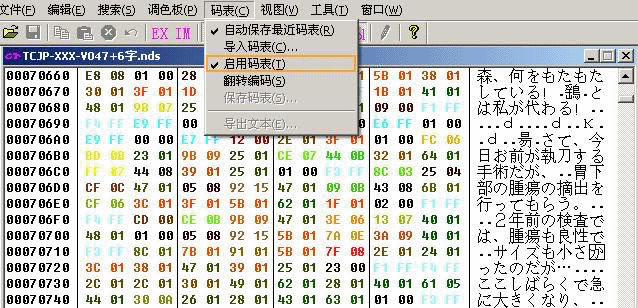
一般NDS游戏对应的码表有两种分别是8140=空格的标准Shift-JIS码表和0000=空格的连续码表(码表的相关内容在后面的教程会进行介绍)。可以大胆地套一下来看看能不能找到文本区。例如超执刀就是用0000=空格那种码表,套入后,应用码表,就可以在CT的16进制模式大概看到文本区的内容。
这对于解读ROM是非常必要的。
另外CT还有一个很有用的功能就是NDS文件系统。
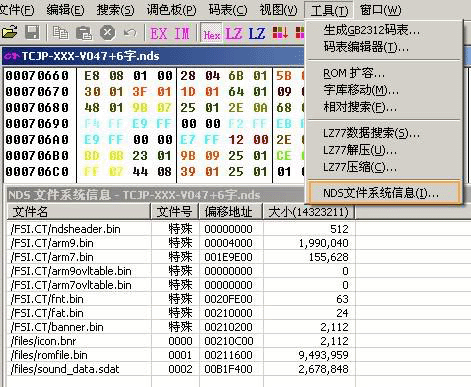
通过这个系统能直观地看到NDS的文件结构,有的ROM甚至会把不同类型和用途的文件以更细致的方式存放,对于了解ROM的结构非常有用。此外在文件系统栏里面还可以分别对不同部分的文件进行导出和导入,分别分析和修改。
CT还有不少强大的功能,待各位在运用中慢慢挖掘吧。总之我觉得开放这个工具的人,只要不是进行过非常规压缩和加密的ROM,大概能破解99%的GBA/NDS游戏了……
二、CT的TILE操作
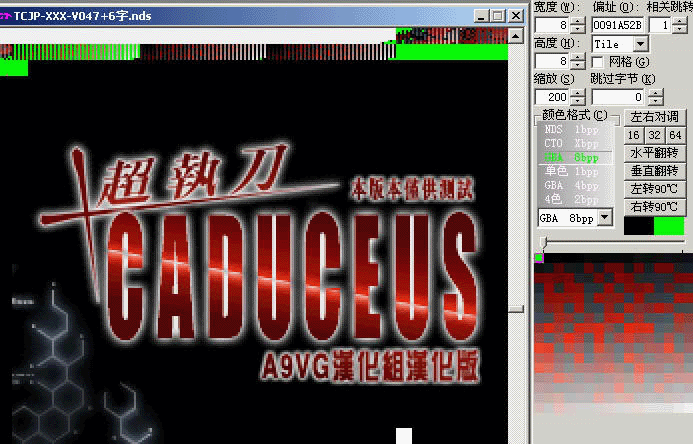
下面用一个简单的例子来说一下CT的TILE操作。
一般在CT里面发现大概图片后,通过调整窗口大小(快捷键SHIFT+方向,但最新版本修改了这个功能的快捷键,用新版本的用户请阅读新版本的说明),另外,缩放的数值建议用200左右进行作业(旧版本用1位数值显示缩放比例)。这样就可以调整至比较工整的情况。(下图已经进行了调整)

但这时看到的颜色是不正确的,因为默认的色版不适配所有图形(正确来说一般都不会适配,但相对的,也比较醒目)。如果想比较好地观察,我建议自己准备一个黑至白的色版(具体色版建立方法留在美工教程说吧),这样图形就能排除颜色的干扰更容易发现,对于未能确定色版的时候是非常方便的。当然,要准备的分别是8bpp(256色)和4bpp(16色)两种,以适应不同格式的图片。

好,回到上面,只要套入了正确的色版,那么图片就可以正常显示了。(当然对于ROM解读阶段,没有必要给每个图片套上正确的色版)

但发现貌似有点瑕疵,那是因为地址偏移还未准确。
用快捷键:CTRL+方向键左右可以微调地址偏移,这个操作非常重要。
调整后,隐藏掉碍眼网格就能看到这个效果了。
三、开始用CT对ROM的解读
用上述的方法就可以大概了解ROM的一下大概构造了。
结合NDS文件系统大概了解一下各个文件分别包含的是什么内容,关键是这个内容在ROM的那个地址。
另外也得进一步分析各个内容的具体位置,
准备几张大白纸,仔细记录好ROM的各个区域分别是什么内容,例如
按地址位置顺序列出:
XXXXXXXX-XXXXXXXX是大标题图,8bpp
XXXXXXXX-XXXXXXXX是小标题图,4bpp
XXXXXXXX-XXXXXXXX是人物全身像,8bpp
XXXXXXXX-XXXXXXXX是字库,1bpp
XXXXXXXX-XXXXXXXX是文本区
XXXXXXXX-XXXXXXXX是音效
…………
这个记录非常重要,一方面可以方便你随时查找需要注意的部分,另一个很重要的作用是:对于未确定地址的内容,可以通过归类和排除法,快速找到其可能的位置。
对于本文的内容,可以参看第一话介绍过的教程的相关部分,并进而学习一些文本,码表的相关知识。
下一话是ROM H的重点,字库的破解部分。敬请期待。
第三话:字库码表篇•初步
https://bbs.a9vg.com/thread-499445-1-1.html
前两话之后,终于进入了有点技术含量的部分了……
当然,考虑到这是篇入门教程,所以我尽量说得详细一点,希望各位不要嫌过于罗嗦和小白……
PS:这篇教程涉及了一些文本导入导出、改图等本系列教程还没有详细讲解的内容。如果没有接触过汉化的朋友,建议参考其他达人写的汉化相关教程有个大概了解,这样可能会比较方便理解本文内容。
另外这篇我把字库和码表合在一起写,而且逻辑结构不算太清晰= =|||
所以一下子可能不太容易消化,可以分部分慢慢阅读。另外还是那句,实践最实际,拿一个工具一边做一般看比直接看能直观得多。
一、码表知识
GBA/NDS游戏一般是怎么显示文字的呢?(其实第一篇教程里面推荐的几篇教程都有说过了,所以我这里尽量简单地重新介绍一下)
上一篇里面提到了用CT套入正确的码表,在16进制模式,文本区就可以看见文本内容了。
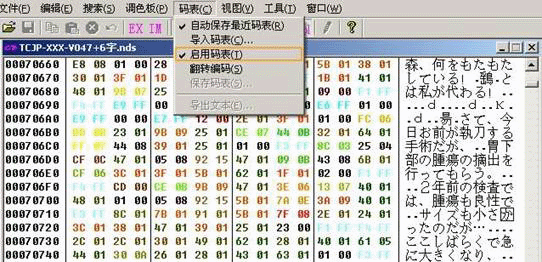
原理就是,ROM的文本区是用16进制代码来写的,例如上图中:
“2年前の检查”对应的16进制就是000706f0行的CD00 CE0B 9B09 4701 3E06 1307这5组16进制编码。而码表就是表示
CD00=2
CE0B=年
9B09=前
4701=の
3E06=检
1307=查
这样的转换关系的列表。
游戏里面也是通过这样的转换关系,从字库挑取字符显示到屏幕上面的。
如果把上面文本区编码改成CD00 CE0B CE0B 4701 3E06 1307
游戏也相应会显示成:2年年の检查,这个也是汉化对文本修改的基础原理。(原文的“检”字不是简体的“检”字,为了说明方便我做了简化处理。)
一般日文版游戏用的是Shift-JIS码表,一个完整的Shift-JIS码表从空格开始,标点,特殊符号,英文字母,平假名,片假名,日语汉字……
例如
8140=
8141=、
8142=。
8143=,
8144=.
8145=•
8146=:
8147=;
8148=?
8149=!
814a=゛
814b=゜
814c=′
814d=`
814e=¨
……
像上面这样的一个对应关系存放的TBL文件(可以用WINDOWS的记事本打开和编辑)
而之前也说过,一般完整的Shift-JIS有2种主要的表示方式,如下图,分别是从8140=空格和0000=空格开始的两种(0000=空格严格来说不是Shift-JIS,而是在Shift-JIS的基础上重新进行自定义的编码)。一般完整的Shift-JIS码表汉字部分是以“亜”开头,以“熙”字作为结束(最完整的是以“黑”字结束,也就是“熙”后面还有一段,但一般情况下因为不是常用字,不少游戏就去掉“熙”字后面的部分了)。下面是这两种码表的分析:
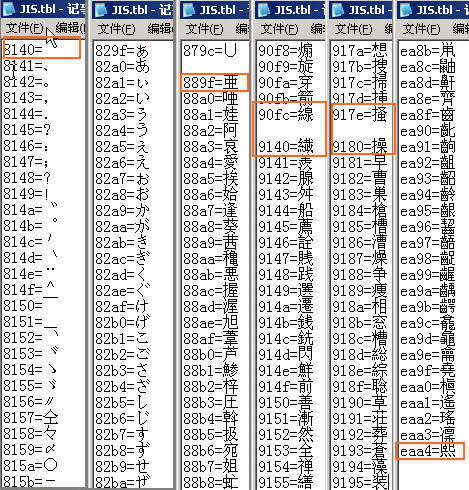
(下图码表无进行16进制的高低位互换,是高位在后的,注意一下)

这样对比不难发现一个问题,8140=空格开始的那种码表,并不是连续的,而是跳过了XX00-XX3F、XX7F、XXFD、XXFE、XXFF(观察第一个码表中间框住有空行的部分)。而第二个码表是完全连续的。为什么呢?相信只要多观察几个文本区编码就会发现问题了。对于第一个码表的文本,跳过这些区域可以有效防止错位搞混的现象,另外也可以留出编码供半角字符,控制符等使用。而第二种码表的控制符则多数以FF00之后的编码作为控制符。
上面说的是导出文本用的码表。只要能套上一个正确的码表就能把文本部分导出来了。
但因为翻译后,不一定会(应该是“一定不会”)用上或只用上原来的字,因为汉化翻译后会用上很多原来字库没有的汉字(例如很多拟声词的字日语是没有的,例如吗,啦,嗯……),而且日语汉字多数是繁体字,要做简体版基本要把字库里面的字改成简体。
那么翻译后要用新的字怎么办呢?
最简单就是在原字库里面添加新字,但是如果只是添加就太浪费空间了,因为翻译后很多原来的字根本用不上,例如完整的Shift-JIS字库里面有6000多个汉字字模,而一般正常翻译之后,实际使用的汉字字模约2000-3000而已,汉化后因为内容跟原来不同,可以在原字库的基础上全部替换成需要用上的字模就行了。
但是问题又来了,这些新的字模写进去后,怎么把它跟文本区的编码挂钩呢?这就需要用新的码表方式,把字库字模和文本区的编码重新对用上,这就需要重新编辑一个新码表。
简单举个例子。例如上面的“2年前の检查”,汉化后变成“2年前的检查”,“的”字的字模我必须找一个位置放它,例如原来码表是4E03=亜,翻译后用不上这个繁体的“亜”字了,我就在字库原来“亜”的位置把它改成“的”字,然后把码表的对应关系改成4E03=的,跟着导入文本的时候,把原来的编码行“2年前の检查”的CD00 CE0B 9B09 4701 3E06 1307
改成“2年前的检查”:CD00 CE0B 9B09 4E03 3E06 1307。那么游戏就会从原来4E03=“亜”的地方提取出现在修改后的“的”字。
而这个新的码表和字库对应关系就是导入文本用的码表,也就是修改后的码表。这就需要重新编辑一个码表了。
以上就是对码表的简单介绍,有个大概概念后下面转入字库部分,先简单了解一下字库和码表的关系。
二、CT的字库HACK
上一话讲了最基础的ROM解读,那么字库一般在ROM里面是什么样子的呢?
下面就是一个例子:
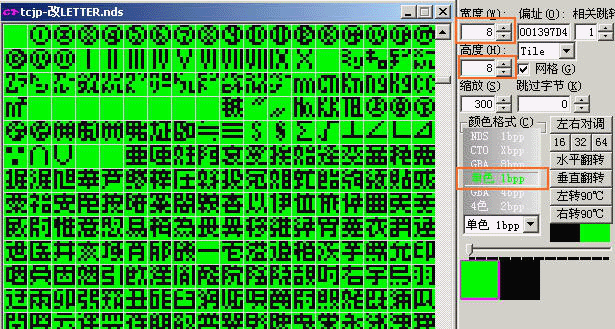
这个是超执刀的小字模字库库,看右边信息就可以看到字模是8X8以下的,用的是1bpp(2色),在游戏中的作用主要是用以标注某些专用名词的上标。而正文的字库是16X16的1bpp(2色)。
【小技巧】:一般判断字库字模用的模式1bpp(2色),2bpp(4色),4bpp(16色),8bpp(256色),可以在游戏里面观察字体,如果是带阴影或边缘模糊(抗锯齿)的,一般就是4色以上的了。另外,如果字库附近有色版信息,从色版的结构(例如是2色,4色还是16色的色版)也能大概判断出字模的显示模式。
在超执刀的这个小字库下面就是16X16的字库了,初看的话,会变成这个样子:
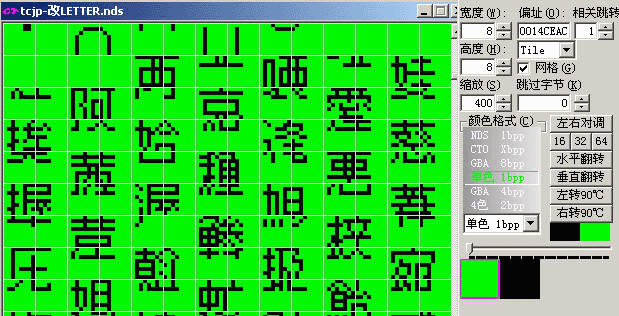
这样有两种调节方法,一个就是强制把窗口宽度调整为16宽度:
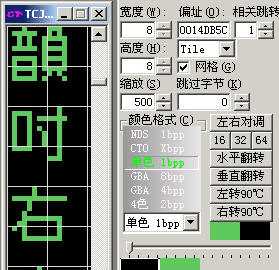
另一种就是比较根本的方法:
上面的错位原因是方格的大小不对(实际是TILE的组合问题,需要进行“水平重组”),在CT的导航栏里面进行相应的调整就行了:
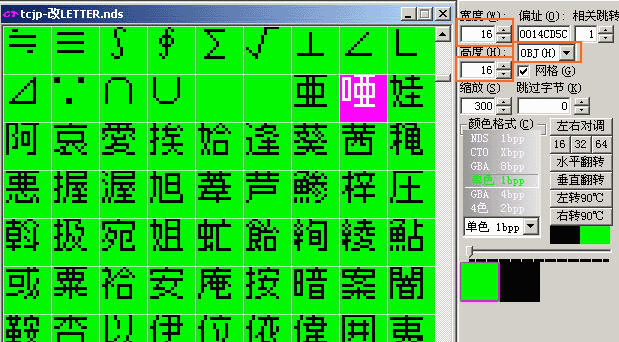
在上图橙色框的部分调整后,然后CTRL+方向键左右,调整正确位移。后就能这样一字一格显示了。
但有的时候字模会比这种混乱,例如出现这样的情况:

这是因为这个ROM的字模之前用了两位16进制来标注这个字模的对应编码,例如在“0”这个字模对应的是D0B800-D0B807这8位的数据,而之前两位是824f,一查码表,刚好824f=0。对付这种字库我们可以用CT的跳过功能,跳过这两位对显示字模无关的字符。
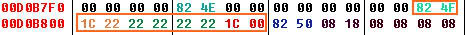
设置跳过数据为两位后,就能完好地显示字模了:
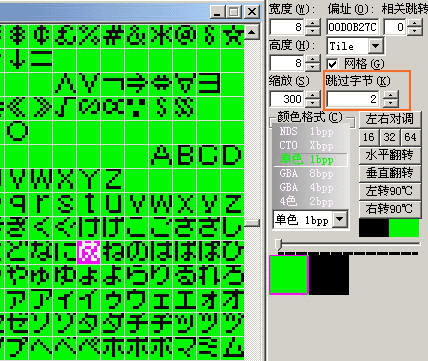
再来,又是一种特别的字库方式,但发现现在也很常见了,就是图片字模:
这种字库是以整张完整的图片而存在,不是一字一格的,所以在普通情况下TILE模式很难观察。这就需要用特殊的方法。
一般这种字库的开头有个别数据表示字库图片的宽度信息,这时观察的时候需要特别注意0010,0020这样的数据(分别表示宽度为256象素,512象素),然后在CT导航栏输入相应的宽度,调整显示模式,就能显示出该字库了。例如某DS游戏的字库:需要用256宽和8bpp(套一个黑白色版)才能正常显示。
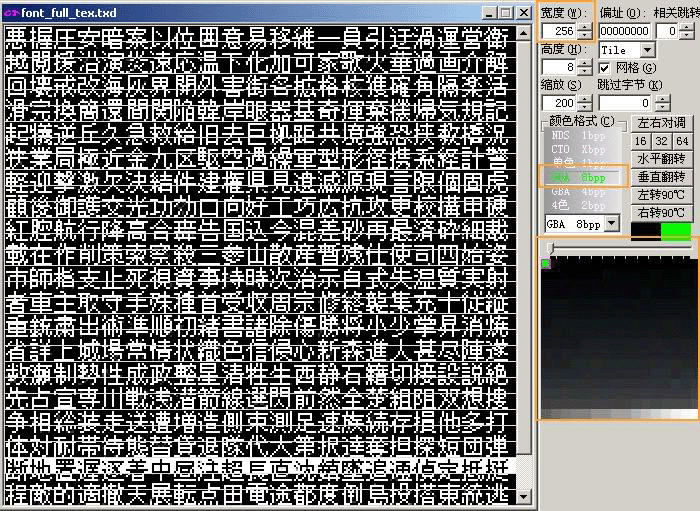
这种字库比较有特色,详细的我留在字库另类扩容的部分来讲解。
总之字库显示好了就能进行具体的字库手术了。
三、编码表
能显示字库后,首先是对照字库确认码表类型。
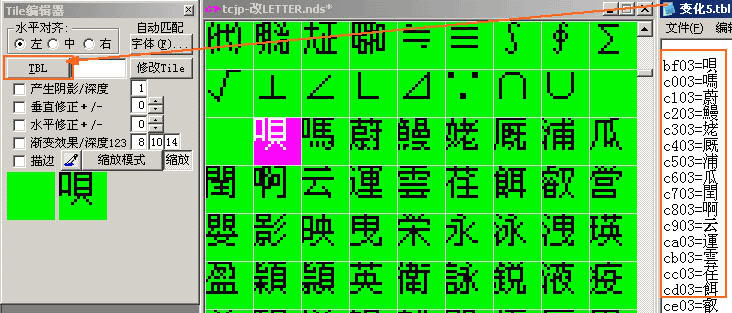
首先看看字库的汉字部分,如果是像上面超执刀的这样:“亜唖娃阿哀愛挨姶逢葵茜穐悪……(一直到)龠堯槇遙瑤凜熙”(最完整的熙后面还有一段直到“黑”字),而且字数明显比较多,那么高兴吧,少年,你面前的是一个标准的Shift-JIS完整字库的ROM,简单来说就是厚道的ROM,有充分空间给你进行字库修正。
你要做的是找一份Shift-JIS码表,看看是那种类型(8140还是0000的),进行确认。然后对应文本区看看是否合用。(8140的标准Shift-JIS码表可以在狼组的网站找到,0000的可以另外找或者自己用8140的改造,因为里面的文字是一样的,只是编码顺序不同,具体改造方法下面会讲。)
如果是如上面的那个图片式字库那样缺了不少汉字,那么先看看它的顺序。
如果虽然缺字,但还是按照Shift-JIS码表的顺序出现汉字,那么是一个精简过的Shift-JIS码表,需要做的是对照字库,研究一下踢除了的字,以及之间的情况。一般来说,这种字库虽然经过精简,但并没有打乱顺序,用标准的完整Shift-JIS码表并不影响文本的导出。但考虑到汉化后需要把用到的汉字重新按新编码装回去,所以最好还是有针对性地做一个精简后的码表进行对照。(另外针对精简字库,如果不考虑扩容的话还得在翻译之后进行减少用字的处理,这个操作和相关原理会在后面的教程讲解。)
如果不但缺字,而且顺序也是乱来的(例如逆转DS……),那么……你就得一个一个地按文字在码表上面的顺序,针对文本区的汉字对照公式,写一个码表,这样才能正常导出文本,以及有针对性地对字库改造。因为这个游戏的字库用的是独立的非Shift-JIS码表排序……这个工程越需要1-2天。
除了上面所说的这种情况,汉化完后,如果如上面提到过的要大规模替换字库,也可能需要新建立一个新的码表关系来导入文本。
针对码表的编辑,下面介绍一些编码表的方法。
最粗糙的方法是用crystalscript(后面简称CS),可以把文字写好在一个UNICODE格式的TXT文件里面,在CS设置为脚本,然后用CS的这个功能就能生产一个码表了。
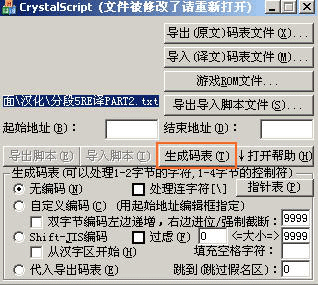
而且如果上面在导入码表里面可以先写好一个第一个字的编码,例如4E03=亜
那么它就会自动把码表里面没有的文字按顺序从上面的序号开始一直排下去。例如4F03=X,5003=Y,5103=Z……
这个方法比较适合的是新建立一个新的导入码表,例如汉化后针对完成的文本大规模替换字库。
而且因为可以直接用翻译好的文本制造码表,非常方便。
当然,产生的码表因为是完全连续的,如果要做出8140那种非完全连续的形式,需要进一步修正(用下面的UE相关方法)。
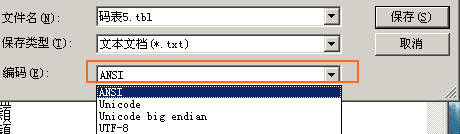
另一个是比较有效率的方法是用UltraEdit(简称UE),但注意的是,UE的对文本功能必须对应ANSI格式才会发挥正常,如果是UNICODE格式,并不能正常。
但偏偏CT和CS却爱用UNICODE,这就需要对码表文件转一下格式,记事本打开,然后另存为的时候选一下ANSI格式就行了。
用UE打开码表文件,然后转换成纵行编辑模式,就能方便地对码表进行编辑了。
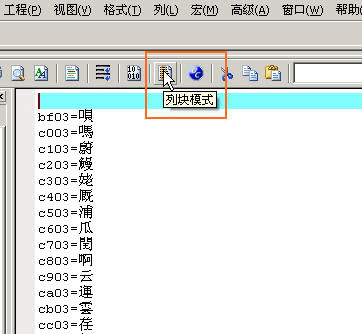
这个功能的主要好处是可以类似OFIICE里面的EXCEL一样对内容进行纵横向的选择和编辑,以及按顺序插入数字或修改。例如用选择范围工具可以选择数行的内容,然后一次进行数字的按顺序插入和修改。具体操作一下就能掌握了,我大概截图说明一下如下,文字就不罗嗦了:

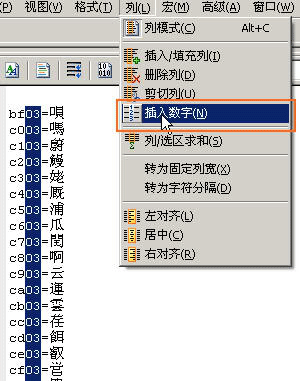
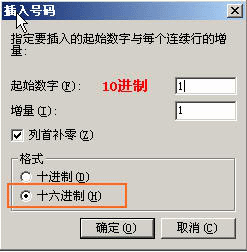
注意一下的就是上面这个序号,上方输入的是10进制数字,不要直接写入16进制的数字。
10进制转16进制可以直接用WINDOWS的计算器的科学型模式来做……如果连这个也不懂用,貌似做ROM HACK的工作就很…orz了。
不过无论何时,对数字的观察多用计算器是必须的,这个要多注意啊。特别是对某些数值的分析方面,尤其重要,多用计算器换算一下,可能会有突破性的发现哦~
(贴这个计算器的贴图我也觉得很orz……,但我的目的是强烈建议各位多利用好计算器这个工具!)
另外这里介绍一个很有用的技巧,是汉化乐园QQ群里面的朋友教的,可以在UE的纵行模式把文字选择好,然后左边编好了序号之后,一次贴上去,这样的操作对码表大改造实在非常好用。

最后的方法就是各位编程达人自己写程序来写码表关系。这个就交给各位编程达人自由发挥了。反正方法是多样地,有效达到目的就行。
码表做好了。可以进行文本的导出和导入了。如前面提到了汉化后有些字原来字库是没有的,那么就需要对字库进行修改。下面正式进入修改字库的部分。
四、改字库
本部分的内容本来应该在上面的部分穿插说明,可能方便理解一点,但考虑到CT强大的理由码表来大规模修改字库的功能,我在说明清楚码表关系后才放在这里说改字库。
CT的TILE工具窗口特别为修改字库进行了强大的优化。首先必须注意的是要在CT里面正确修改字库,必须先把它设置成1格里面放一个字的模式(参照前面的字库正确显示方法)。
然后就可以使用TILE工具修改了。
直接用TILE工具可以像画笔一样一笔一划地写入,当然,更方便的是设置好字体后直接导入。方法如图:
在文字窗口输入要改的汉字,然后设置好字体后就会在左下角预览窗口显示修改后的效果。然后按修改TILE按钮就能改好了。
另外下面的复选框是给文字加上阴影,描边等效果的,这里就不多说,大家在实践中摸索就性。(阴影、描边等需要是4色(2bpp)以上的字模才能有效)
PS:本教程做的有的粗糙……其实正确的文字位置应该还要水平位移向右1象素(在下方复选框设置)才跟原来的相吻合= =|||
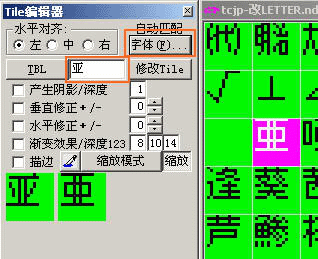
但CT的强大不是这么一个一个字地改,而是可以直接按码表的顺序,一次过把文字全部写入到字库里面。
首先准备好编辑好的码表(例如导入文本用的新码表),然后像上面一样设置好字体字型。预览一下。
然后按下TBL,选用需要的码表,然后一瞬间,文字就会按码表的顺序一个一个全部写入到字库里面了。快捷,方便,强大!(如下图)
当然,修改字库还有另外的方法。就是美工法。
这个方法虽然比较麻烦,但是却适用性比较强。例如对一些字体字型,文字显示效果(阴影描边)进行灵活处理,对应图形字库的修改(例如那些不能一个字放一格的字库)。而且对于小规模修改字库也很方便。
当然这个部分最好结合后面的美工教程参考,这里只是简单说一下。如果有美工基础的朋友应该就不难理解了。
首先把需要修改的码表部分用CT导出BMP文件。
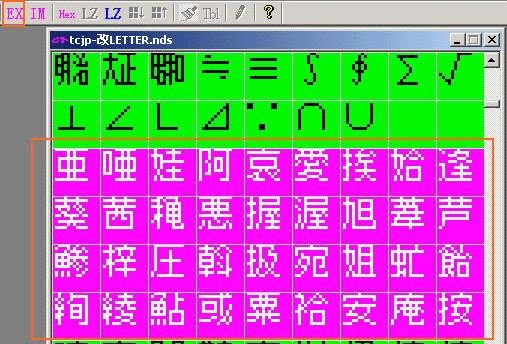
导入到PS(PHOTOSHOP,作为美工不会不知道PS吧……)
导入的图片是索引色,为方便转换成RGB色。
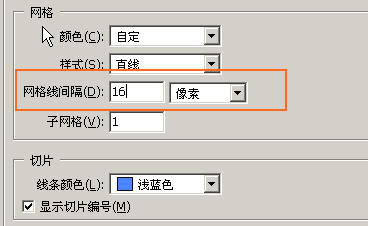
为了修改方便,在PS里面设置跟CT一样的参考线网格,方法如下:
编辑,首选项,网线和网格
设置成根CT一样的象素,16X16象素(px)(注意单位)
视图,显示,网格
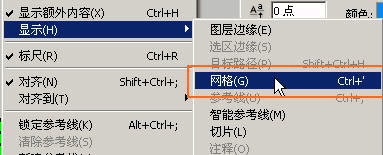
这样就能显示跟CT一样的参考线网格了。

然后建立背景层覆盖原层,在上面建立文字层,通过文本段落工具配合参考网格调整好文字大小,行距和字间距。
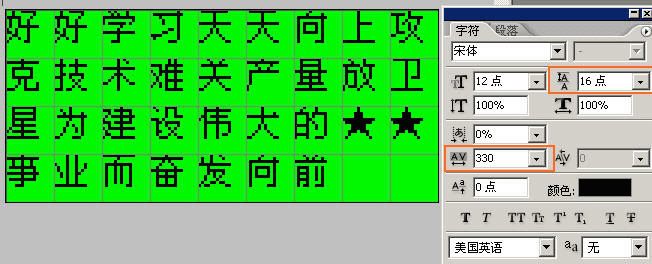
修改好后转回索引色,用WINDOWS画笔校正一下,重新导入到ROM里面相应字库位置就行了(这个流程的具体操作参考后面的美工教程,或者网上的一些汉化相关美工教程。)
以上就是字库和码表的一些基础。至于关于图片字库的特殊性和修改方法,以及特殊字库扩容技巧,我将结合JSS的字库另外写一个教程。但之前提到过不会在8月8日前透露JSS的相关技术细节,所以那个教程需要等一下。字库部分就暂时到此为止。
后面就会有文本导出导入的教程,敬请期待。
感谢汉化乐园的各位提供的本文DEBUG意见。